
Stell Dir eine Welt vor, in der Künstliche Intelligenz (KI) so fortschrittlich ist, dass sie menschliche Kommunikation nahezu perfekt nachahmen kann. Ist das eine aufregende Vorstellung oder eher beängstigend? In jedem Fall spielen menschliche Daten eine zentrale Rolle bei der Realisierung dieser Vision. Von Reddit bis Meta: In diesem Beitrag beleuchten wir, warum menschliche Daten für KI-Modelle (z. B. ChatGPT) so wichtig sind und wie sie zur Entwicklung fortschrittlicher generativer KI-Systeme beitragen.
Die Begrenztheit der verfügbaren Daten
Ein zentrales Hindernis bei der Entwicklung leistungsfähiger KI-Modelle ist die begrenzte Verfügbarkeit hochwertiger Daten. Während KI-Modelle theoretisch unbegrenztes Potenzial haben, hängt ihre tatsächliche Leistungsfähigkeit stark von der Qualität und Vielfalt der Trainingsdaten ab. Ein prägnantes Beispiel für die Endlichkeit von Daten ist Googles Buch Projekt zum Scannen und Digitalisieren von Millionen Büchern. Diese wertvollen Informationen sind feststehend und ändern sich nicht. Sobald sie in KI-Modelle integriert wurden, sind sie ‚verbraucht‘ und bieten keinen kontinuierlichen Fluss neuer Daten. Aber was wäre, wenn wir Zugang zu einem ständig aktualisierten Strom von Daten hätten? Hier kommen Plattformen wie Reddit und Meta ins Spiel.
Visionäre Strategien für Echtzeitdaten
Um die Relevanz und Aktualität von KI-Modellen sicherzustellen, ist es daher entscheidend, Zugang zu dynamischen Datenmärkten zu haben, die kontinuierlich aktualisierte Informationen bereitstellen. Große Plattformen wie Meta und Reddit bieten eine Fülle aktueller, menschlich erzeugter Inhalte. Visionäre Unternehmen legen bereits jetzt die Grundsteine, um in Zukunft an diesen Echtzeitdaten teilzuhaben und somit fortschrittliche generative KI-Systeme zu entwickeln. Menschliche Daten sind besonders wertvoll, da sie eine natürliche und vielfältige Darstellung menschlicher Kommunikation und Erfahrungen bieten. Ein Beispiel dafür ist die Partnerschaft zwischen OpenAI und Reddit.
Partnerschaft zwischen OpenAI und Reddit
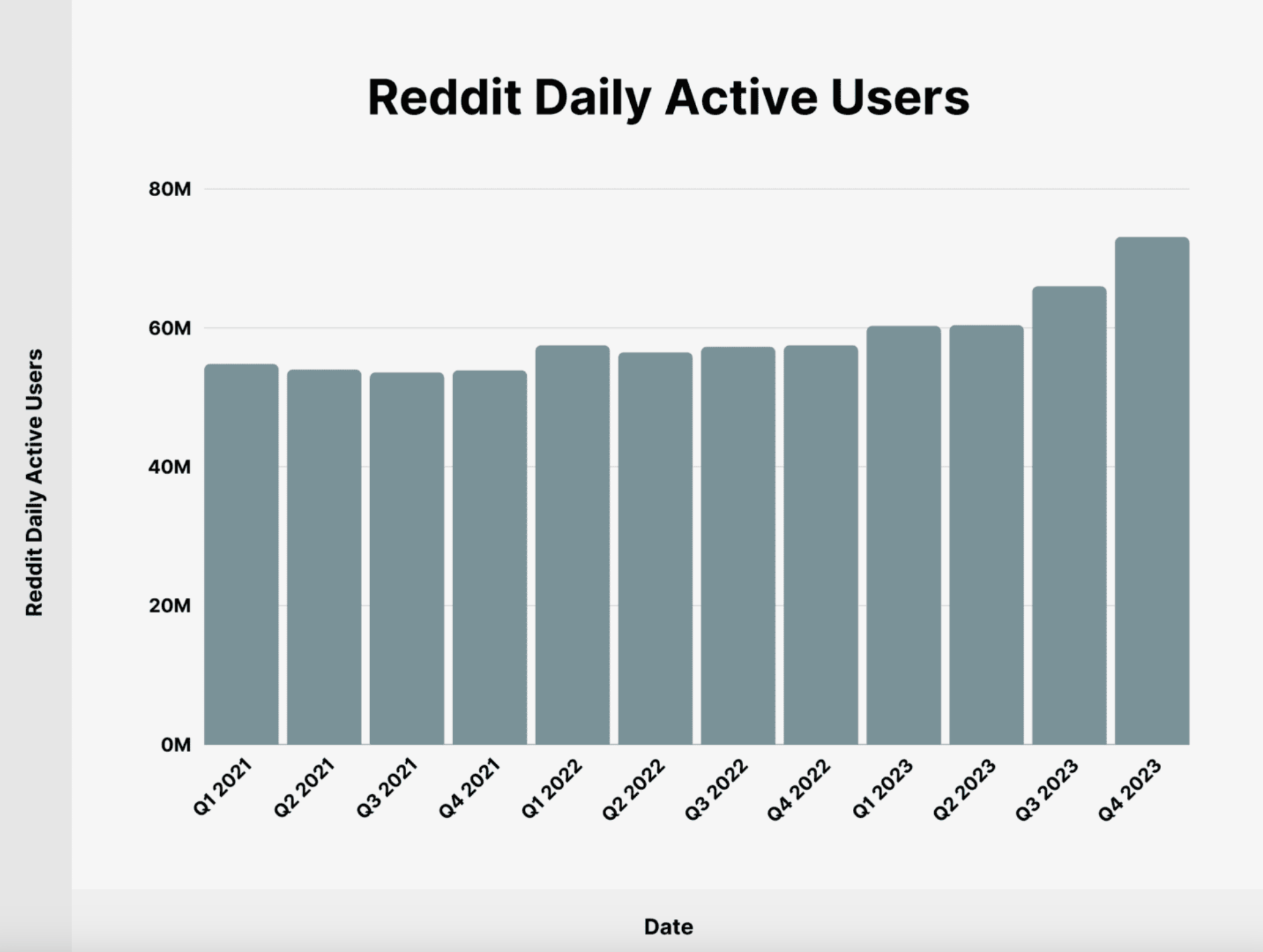
Reddit, eine der größten Online-Communitys und Diskussionsplattformen, bietet eine außergewöhnlich vielfältige Quelle menschlicher Kommunikation. Mit über 73 Millionen täglich aktiven Nutzern, die in verschiedenen Subreddits eine breite Palette von Themen und Interessen diskutieren, stellt Reddit eine wertvolle Ressource für das Training von KI-Modellen dar. Erst kürzlich hat OpenAI bekannt gegeben, dass sie eine Partnerschaft mit Reddit eingegangen sind, um ihre KI-Modelle weiter zu trainieren. Die natürliche Sprache, informelle Kommunikation und aktuellen Diskussionen auf Reddit ermöglichen es KI-Modellen, ein breites Spektrum an Sprachmustern und Kontexten zu erlernen. Diese Daten sind besonders nützlich für die Entwicklung von Modellen der natürlichen Sprachverarbeitung (NLP), ähnlich wie die Daten, die Meta nutzt.
Metas Einsatz von Nutzerdaten zur KI-Entwicklung
Ähnlich wie Reddit nutzt auch Meta (Facebook, Instagram etc.) die umfangreichen Daten seiner Plattformen, um KI-Modelle zu trainieren. Diese Daten umfassen öffentlich zugängliche und lizenzierte Informationen sowie Beiträge, Fotos und Bildunterschriften von Nutzern. Meta betont die Bedeutung einer verantwortungsvollen und ethischen Datennutzung, einschließlich der Einhaltung von Datenschutzrichtlinien und der Sicherstellung der Privatsphäre der Nutzer. Durch die Nutzung dieser Daten kann Meta KI-Modelle entwickeln, die menschliche Kommunikation besser verstehen und realistische Inhalte generieren. Die Fähigkeit von Meta, auf eine Vielzahl von Daten zuzugreifen, ermöglicht es ihnen, fortschrittliche und vielseitige KI-Features zu entwickeln. Doch diese Entwicklung bringt auch Herausforderungen und Probleme mit sich.
Herausforderungen und Problematiken
Ein häufig übersehenes Problem ist das Training von KI-Modellen ausschließlich mit von anderen KI-Modellen generierten Daten. Dies kann zu einem Verlust an Vielfalt und Qualität führen, da KI-generierte Daten tendenziell vorhandene Muster und Stile wiederholen. Zudem können Fehler, Fake News und Ungenauigkeiten verstärkt und bestehende Verzerrungen und Vorurteile übernommen werden. Menschlich erstellte Daten hingegen bieten eine breitere Vielfalt, kreative Ausdrucksweisen und eine realistischere Repräsentation der menschlichen Erfahrung. Diese Vielfalt ist entscheidend, um die Sprachfähigkeiten von KI-Modellen zu verbessern und ihre Anwendungsbereiche zu erweitern.
Die Kombination von menschlich erstellten und KI-generierten Daten
Die Kombination von menschlich erstellten Daten und KI-generierten Daten ist entscheidend für die Entwicklung leistungsfähiger KI-Modelle, die natürliche Sprache verstehen und innovatives Wissen generieren können. Menschliche Daten bieten die notwendige Vielfalt und Kreativität, während KI-generierte Daten dabei helfen können, spezifische Muster und Trends zu erkennen und zu nutzen. Diese Kombination ermöglicht es, die Stärken beider Datenquellen zu nutzen und gleichzeitig ihre Schwächen zu minimieren. Daher ist die Kombination von menschlich erstellten und KI-generierten Daten entscheidend.
Zukunftsperspektiven
In Zukunft wird das Lernen von natürlichem Sprachverhalten, aber auch von Bewegungsabläufen von Robotern weiter voranschreiten. Durch die Fortschritte in der KI-Technologie werden wir nicht nur intelligente Systeme erleben, die menschliche Sprache verstehen, sondern auch Roboter, die komplexe Bewegungen und Aufgaben ausführen können. Diese Entwicklungen versprechen, unser Leben in vielerlei Hinsicht zu erleichtern und zu bereichern, indem sie neue Möglichkeiten für Automatisierung, Assistenzsysteme und personalisierte Dienstleistungen eröffnen. Hier ein Beispielvideo von Teslas Optimus:
Fazit
In der sich ständig weiterentwickelnden Welt der Künstlichen Intelligenz sind menschliche Daten das Herzstück, das die Maschinen zum Leben erweckt. Von Reddit bis Meta, diese Plattformen bieten eine unerschöpfliche Quelle an menschlichen Daten, die für die Entwicklung und Verbesserung von KI-Modellen unerlässlich sind. Doch während wir uns auf diese Daten verlassen, dürfen wir die Herausforderungen und ethischen Bedenken nicht aus den Augen verlieren. Es ist wichtig, dass wir einen verantwortungsvollen Umgang mit Daten pflegen und stets die Privatsphäre und Sicherheit der Nutzer gewährleisten. Die Kombination von menschlich erstellten und KI-generierten Daten bietet uns die Möglichkeit, die Stärken beider zu nutzen und ihre Schwächen zu minimieren. Mit Blick auf die Zukunft können wir gespannt sein, wie diese Synergie die nächste Generation von KI-Systemen prägen wird.
P.S.: Durch die Zusammenarbeit von Mensch und Maschine haben Wissenschaftler mithilfe künstlicher Intelligenz die ersten neuen Antibiotika seit über 60 Jahren entdeckt.
